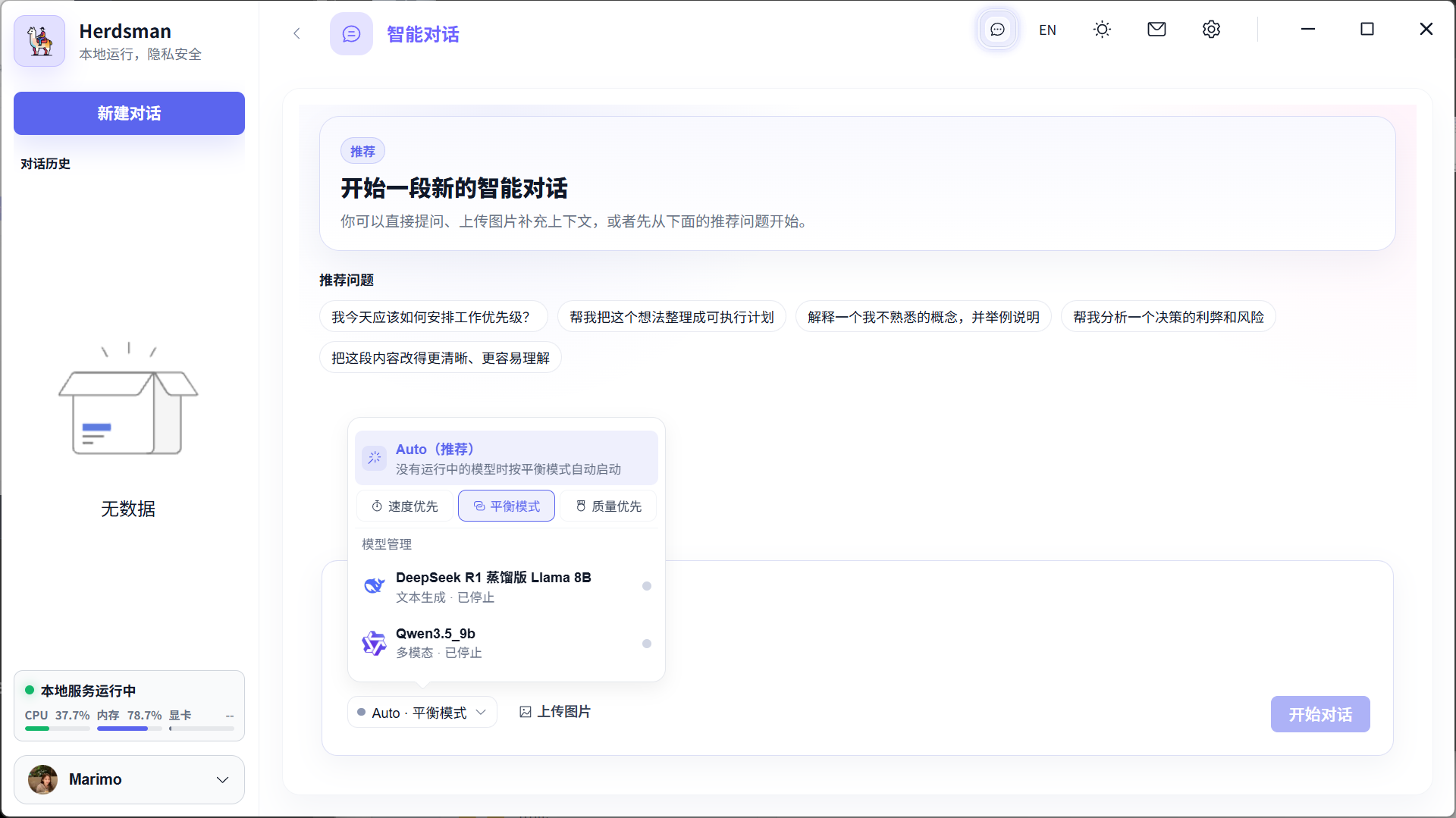
Smart mode selection
Choose speed, balance, or quality; Auto mode picks the best local model for you.
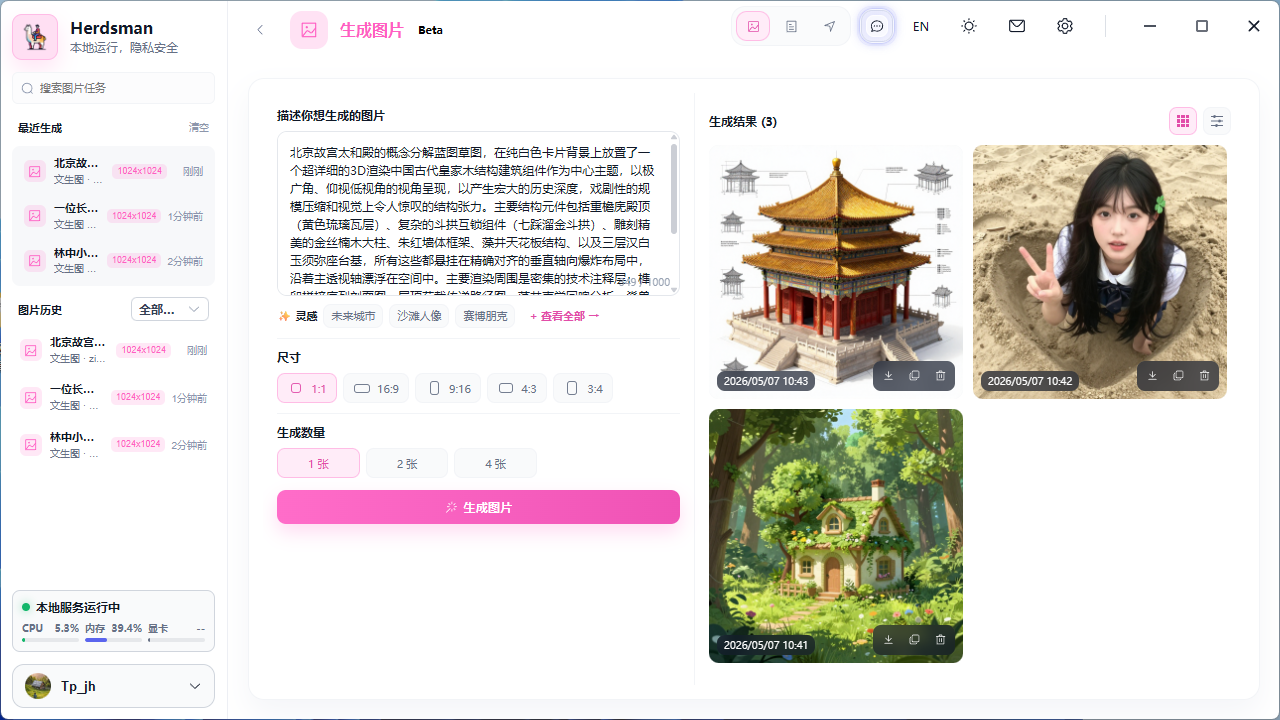
Rich image generation
Text-to-image, image-to-image, and precise edits—creative workflows stay in your control.
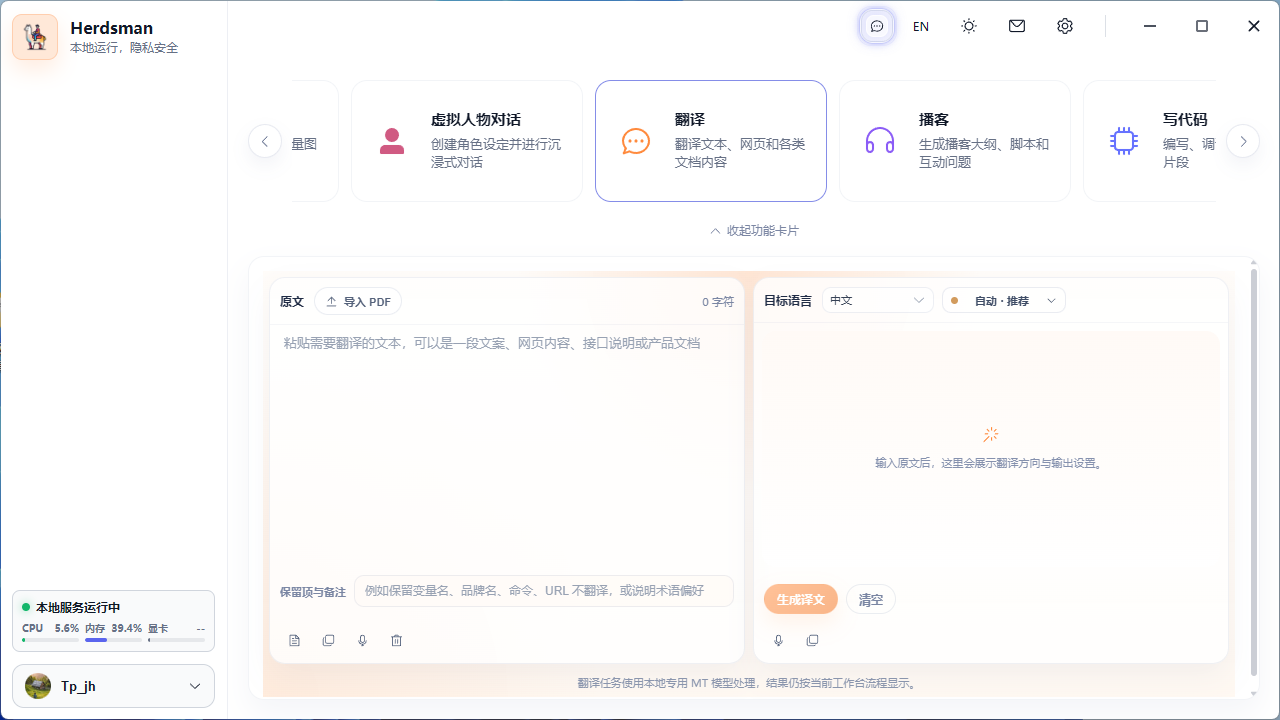
Multilingual translation
Upload documents and translate in one click with a style you choose.
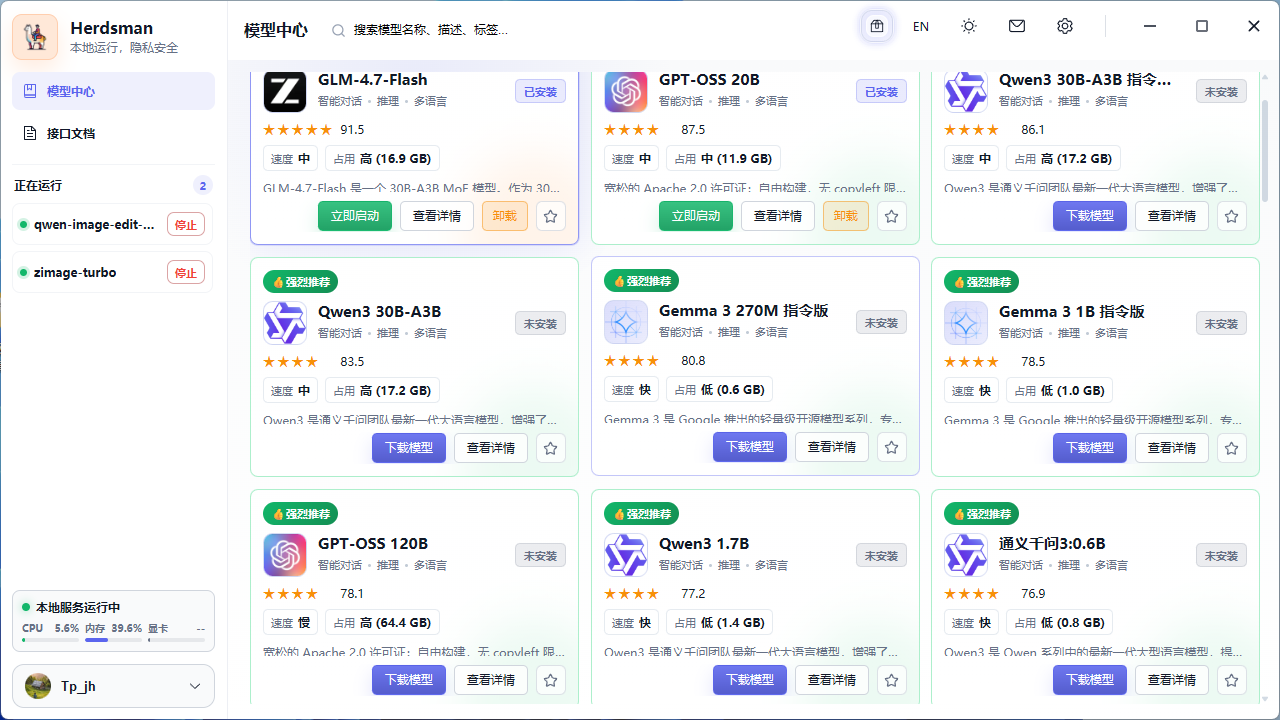
Broad model library
Hundreds of models to cover diverse AI workloads and modalities.
Why Choose Herdsman Al Local Engine
A next-generation engine built for high-performance AI inference
Lower Token Costs
Herdsman Al Local Engine deploys large models on your local hardware. From long-document summaries to nonstop code generation, your inference cost is effectively just electricity.
Rich Hardware Ecosystem
Deeply optimized for Windows with recommended hardware tuning and VRAM allocation strategies that remain stable even under parallel workloads.
Faster Responses
Inference paths and model weights are tuned for speed, making local models easy to use for beginners while still exposing model APIs for power users who want full control.
Privacy & Security
Your data stays your asset. Offline-capable local execution reduces the risk of sensitive information leaking to the cloud at the source.
Multi-Model Support
Built-in support covers dozens of modern multimodal and language models, including the OpenClaw family, with one-click download-to-deploy workflows.
Gets More Personal Over Time
By combining local files, habits, and schedules, FlowyAIPC with Herdsman Al Local Engine can iteratively adapt to your own data and workflows.
Significantly faster Qwen3.5 on Intel Panther Lake platforms
| Model | FA | Build | 512 tok | 1k tok | 2k tok | 4k tok | 8k tok | 16k tok | 32k tok | 256k tok |
|---|---|---|---|---|---|---|---|---|---|---|
| Qwen3.5-35B-Q4_K_M | FA=1 | Base | 808.7 | 956.5 | 898.6 | 776.3 | 615.7 | 433.2 | 266.1 | 266.1 |
| FA=1 | Our | 1111 | 1183 | 1224.6 | 1195 | 1127.6 | 1106.6 | 825.3 | 825.3 | |
| FA=1 | Speed up our/base | 1.37x | 1.24x | 1.36x | 1.54x | 1.83x | 2.55x | 3.10x | 3.10x |
| Model | FA | Build | 512 ctx | 1k ctx | 2k ctx | 4k ctx | 8k ctx | 16k ctx | 32k ctx | 256k ctx |
|---|---|---|---|---|---|---|---|---|---|---|
| Qwen3.5-35B-Q4_K_M | FA=1 | Base | 31.1 | 30.4 | 30.2 | 28.6 | 26.8 | 24 | 20.2 | 20.2 |
| FA=1 | Our | 38.93 | 38.33 | 36.89 | 36.44 | 35.47 | 32.04 | 35.5 | 37 | |
| FA=1 | Speed up our/base | 1.25x | 1.26x | 1.22x | 1.27x | 1.33x | 1.33x | 1.76x | 1.83x |
3.10x
Max Prefill uplift
32k token context
1.83x
Max Decode uplift
256k token context
2.01x
Avg Prefill uplift
Across all context sizes
1.41x
Avg Decode uplift
Across all context sizes
Save Token Costs
Prevent overflow | Save tokens | Cut costs precisely
Use lightweight L0 and L1 context for planning, then fetch L2 detail through URIs only when execution needs it. This sharply reduces token cost and avoids truncation risk.
L0 Summary
One-line context, quick judgment
L1 Core
Key context for planning
L2 Detail
Full detail loaded on demand
Privacy & Security
If uploading chats, documents, or photos to the cloud feels risky, Herdsman Al Local Engine keeps that data on your own machine so control stays with you.
Local Storage
All data stays on the local device instead of being uploaded, giving you full ownership and control.
End-to-End Encryption
Data transfer uses bank-grade encryption standards to keep information protected in transit.
Privacy Protection
No behavior analytics, no tracking, and no hidden collection of user activity data.
Faster Responses
Less network dependency, Windows-ready, lower cost